STREAM DECKで遊ぶために学んだPythonのこと
STREAM DECKについて
拡張キーボードと呼ばれるもので、ボタンにショートカットを割り当てたりできるものです。
Linuxでも使えますが、Linuxで使えるGUIアプリ(streamdeck-ui)がイマイチなので、使う気になれなかった...のですが、Pythonのライブラリがあるので、自分で作れば良くね?と思って、作りました。

作ったもの
Linuxで使うようのものなのですが、Active Windowの切り替えにしか、Linuxに依存するコードがないので、もうちょいなんとかしたら良いんじゃないかとも思いつつ、他のOSなら別にこんなものを使う必要もないのだろうと思って、あまりやる気が起きないです。そして、一通り作ってしまったので、これ以上やるかな...というところもちょっと謎。
上のコードの中に、下記のような機能が入っています。
- YAMLでキーに何を表示、割り当てられるかを書ける
- Active Windowの切り替えでページを変えられる
- アラート機能(定期的に何かをチェックして、ページを切り替える)
- ゲーム
- 記憶力系
- 神経衰弱(対戦あり)
- 三目並べ(対戦)
- もぐらたたき
- アプリ
- アナログ時計
- ストップウォッチ
- カレンダー(現在年月日表示)
久しぶりのPython
10年以上前くらいに、Mailmanの拡張みたいなことをした覚えがあります。遠い昔なので、今回、初めて触るくらいな感じでしたが、色々やらかしつつも、割と簡単に書けました(まだ間違えてる可能性は大ですが)
今回、目的から入ってしまったので、いつもはチュートリアルみたいなのをやるんですが、特にやらずに書いてしまいました。あんまり良くないですね。 学習時間&コード書いた時間は大体2,3日くらいではないかと思いますので、まだ中途半端な理解のところばっかです。
使ったPythonのバージョン
Ubuntuのパッケージで入れたのそのまま使っていて、3.10.4となります。
実現したかったこと
下記みたいな感じでやりたいことが増えていってしまった感じです。
最初の
- 設定をGUIじゃなくて、設定ファイルっぽく書きたい
- Active Windowの切り替えを検知して、ページの切り替えをしたい
やってるうちにやりたくなったこと
- 設定は動的に読み直したい
- アプリみたいなものも作りたい
- ゲームも作りたい
さらにやりたくなったこと
- アプリやゲームも設定ファイルから読み込ませたい
関数定義(def)
def 名前(引数): # 処理 return ret
引数にデフォルト値をつけたい
def hoge(x, y, z=3): return z
この場合、
hoge(1,2) # 3が返ります
ただ、default値が設定されていないものは、必須となりますので、
hoge()
は、エラーになります。
また、先にdefault値あり、後でなし、みたいな指定はできません。
def hoge(x=1, y, z): return z
これは、エラーになります。
関数内でglobal変数を使うとき
def hoge(args): global X
のようにします。
signal
Active Windowの切り替えなんですが、当初、スレッドとかどうせ難しいんじゃないかなぁ、と敬遠して、fork & signal でやっていました(やらなきゃよかった)。
import os current_pid = os.getpid() child_pid = os.fork() if child_pid == 0: # 子プロセスで、stream deck のメイン動作 else: # 親プロセスで、active window のチェック
子プロセス側に、こんな感じで、singal に対するhandlerを登録し、
_handler_switch = lambda signum, frame: self.handler_switch(signum, frame) signal.signal(signal.SIGUSR1, _handler_switch) # sinbal to check active window switching
親プロセスで、切り替わりが判明したら、下記のように、signal を送っていました。
os.kill(self.child_pid, signal.SIGUSR1)
なお、親プロセスには、SIGCHLDを受け取れるようにしておきましょう。
signal.signal(signal.SIGCHLD, lambda signum, frame: self.handler_sigchld(signum, frame))
とやって、まぁ、動いていたのですが、pythonのthreadは思ったより簡単だったので、後々threadに変更しました。
クラスの書き方
signal の例を見てわかるとおりですが、今は、Classで書いてますが、最初はそうではなかったです。 Classは下記のように、定義します。
class ClassName: class_var = None # クラス変数 # コンストラクタ def __init__ (self): self.member_var = None # メンバ変数 pass # メソッド def method(self, args): pass
self が必要なので、Perlが頭によぎりました。
使う側では、
from "パス" import ClassName i = ClassName() i.method(1)
のようにして、インスタンスを取って、メソッドを呼び出すことが出来ます。
サブクラス
サブクラスはクラス名の横に(親クラス)のように定義します。
class Parent: def __init__(self, args): if args.get("data") is not None: self.data = args["data"] class SubClass(Parent): def __init__(self, args): super().__init__(args) # 親を呼びたい場合。何もしたくなければ、pass と書いておけばよいです。
pass
何回かでてきましたが、python には、pass という文法上書かないと行けないけど、何もしたくない場合に、使うものがあります。
コンストラクタを定義しないといけないけど、def __init__(self): の次の行に何も書かないとエラーなので、passとだけ書いておく、と言ったふうに使います。
def __init__(self): pass
文字列(str)、数字(int,float)、リスト(list)、タプル(tuple)、辞書(dict)
str
"hoge" 'hoge'
特に、single quote, double quoteでの差はないです。
文字の部分を取る
"hoge"[0] # h "hogehoge"[1:3] #og
フォーマットして文字列化する
下記のように{} に当てはまりますが、
"{}.{},{}".format(1,2,3) # 1.2.3 となる
順番を明示することも出来ます。
"{2}.{1},{0}".format(1,2,3) # 3.2.1 となる
sprintf的なことをする
また、sprintfのようなことをしたければ、
"{2:02d}.{1:3d},{0:6.3f}".format(1,2,3) # 03. 2, 1.000 のようになる
int, float
a = 1 # int b = 1.1 #float
文字列 + 数字みたいなことをするとエラーになります。
a = '1' print(a+1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can only concatenate str (not "int") to str
数字を文字列にする場合は、str(i) のように、str で囲めばよいです。逆なら、int,floatで囲めばOK。
リスト
array = [1,2,3,4] len(array) # 4 array[0] # 1 array.append(1) # 末尾に追加 array.insert(0, "A") # 先頭に追加 array.pop(-1) # 末尾を取る array.pop(0) # 先頭を取る
tuple
[] ではなくて、()で囲めば、tupleとなります。
t = (1,2,3,4) t[0] # 1 t[3] # 4
ですが、増やしたり、削除したり操作するようなことはできない(count, index しかメソッドがない)ので、固定的な決まりのデータ集合(時、分、秒とか)に使うと良さそうです。
tupleはdictのキーにも使えます。
tupleの存在をブログを書きながら思い出したので、tupleで書くべきところをリストで書いちゃってるなーと...いうところが、結構あるなー。
dict
dictは、キーバリュー構造。他言語ならハッシュとか、ハッシュマップですね。
conf = {
"A": {
1: 123,
2: 223,
},
}
こんな感じです。
dcit のサブクラスにCounterというのもあるようですが、調べていません。
dict のキーを取得する
for key in conf.keys(): print(key)
dict に対するアクセス
値を取るには、
conf["A"]
のようにしてアクセス出来ますが、未定義のものについてアクセスするとエラーになります。そのため、
conf.get("A")
のようにしてアクセスします。
a = conf.get("A")
if a is not None:
print("Aがあるよ")
といった感じですね。
dict を key/valueセットで取り出す
for item in conf.items(): print(i[0], i[1])
といった感じです。
条件、比較
and, or, is, not, ==, =!
なお、先の例にもありましたが、Pythonでは、おなじみの&&や||は使えず、and or で条件を書きます。
True, False, Noneや、typeの比較に関しては、is が使えます(==, != でも良い)。他は、==や!=で比較します。
リストの中にある値がふくまれているかどうか
array = [0,1,2] if n in array: print("{} is in the list".format(n))
型のチェック
typeを使い、strやintかどうかを調べます。
if type(a) is str: print("文字列")
無名関数
lambda 引数,.. : 式 のように書きます。
f = lambda arg: 10 + arg f(10) # 20
yaml を読み込む
最初はハードコーディングしていたのですが、毎回起動し直すのも面倒なので、動的に読み込むことにしました。
import yaml import time import os # 省略 def load_conf_from_file(self): statinfo = os.stat(self._config_file) if self._config_file_mtime < statinfo.st_mtime f = open(self._config_file) conf = yaml.safe_load(f) self._KEY_CONFIG = conf["key_config"] self._config_file_mtime = statinfo.st_mtime
こんな感じです。
yaml には load と safe_load の2つのメソッドがありますが、セキュリティ上の理由で safe_load を使うべきです。loadは互換性のために残されているだけです。
os.stat から取れる、statinfo には、st_mtime というメンバ変数があり、変更時刻が入っています。 こちらを、インスタンスのメンバに持たせてやって、古くなったら読み直しするようにしています。
thread
当初 fork & signal でやっていたものの、やっぱり threadでやるべきだよなぁ、ということでthreadにしました。 thread間のデータのやり取りに、Queue, Event, または、単にインスタンスのメンバ変数という方法もあります。
thread とQueue
簡単なthreadプログラムは、下記のような感じになります。
import threading import time import queue import sys queue = queue.Queue() def put(): i = 0 while True: i += 1 queue.put(i) time.sleep(1) try: v = queue.get_nowait() if v["stop"]: break except: pass sys.exit() def check(): while True: v = queue.get() print("receive: {}".format(v)) if v > 2: stop = True queue.put({"stop": 1}) break sys.exit() t1 = threading.Thread(target=put,args=()) t2 = threading.Thread(target=check,args=()) t1.start() t2.start() t1.join() t2.join()
queue はthread間でメッセージのやり取りができますが、get の場合、取るものがないとblockします。
get_nowait() (get(False)と同じ)は、blockしませんが、エラーになるので、try が必要になります。
ですが、3つ以上のthreadで使うには使いにくいですね。
thread 間でインスタンスのメンバ変数にアクセスできる
最初、queueも使っていたのですが、使いにくい...というか、インスタンスの場合、何も考えずに値を共有できるので、そっちにしました。
import threading import time import sys class Dummy: stop = False def __init__(self): self.i = 0 def put(self): self.i = 0 while True: time.sleep(1) self.i += 1 if self.stop: break sys.exit() def check(self): while True: time.sleep(1) print("set in put: {}".format(self.i)) if self.i > 2: self.stop = True break sys.exit() if __name__ == '__main__': d = Dummy() t1 = threading.Thread(target=lambda: d.put(), args=()) t2 = threading.Thread(target=lambda: d.check(), args=()) t1.start() t2.start() t1.join() t2.join()
このようにするだけで、put 側で、setした値が、check側で読み取れますし、check 側でセットしたstopについても、put側で読み取れます。
滅茶楽(ロックとかしないといけないケースはあると思いますが、今回は特に不要でした)。
クラスと main を一緒に書きたい
先程の例のように、クラスとmainを一緒に書きたい場合は、
if __name__ == '__main__':
この後に、プログラムを書けばよいです。
try 構文
例外を補足するために、tryが使えます。
try: # 処理 except Exception as e: print(e) else: # 省略化 # 正常処理 finally: # 省略化 # 共通処理
Exceptionのところは、具体的なエラーを書くことで、個別のエラーに対する処理が書けます。Exceptionは何にでも引っかかります。
例外時に何もしないなら、
except: pass
のように書くと良いです(いや、良くないのでは?)
Loop処理
for や while が使えます。
for
for i in range(0, 5): print(i)
while
while True: i += 1 print(i) if i> 10: break
ネストしたループのbreak
若干注意が必要と言うか、label的なものがないんですね。
for i in range(1, 5): for n in range(1, 5): print("{} * {} = {}".format(i, n, i*n)) if i * n > 15: break else: continue break
こんな感じで書くようです。わかりにくい。
下記で良いんじゃない?と思いますね。
found = False for i in range(1, 5): for n in range(1, 5): print("{} * {} = {}".format(i, n, i*n)) if i * n > 15: found = True break if found: break
random
0から9までのランダムな数を返す。
random.randint(0, 9)
0.2から10までの、ランダムな浮動小数点の値を返す。
random.uniform(0.2, 10)
スリープ
少数を渡してもOKです。
time.sleep(n)
datetime
日付はこんな感じ。
d = datetime.datetime.now()
y = now.year
m = now.month
d = now.day
wday = now.week_day() # 0がMonday, 6 がSunday
# 英語に変えるなら、こんな感じ
wday = {0: "Mon", 1: "Tue", 2: "Wed", 3: "Thu", 4: "Fri", 5: "Sat", 6: "Sun"}[now.weekday()]
# てか、strftime使えばいい
wday =- t.strftime("%a")
package とモジュール
package はディレクトリ
package_name |- __init__.py |- module_a.py |- module_b.py
ソート
sorted を使います。
tuple, list
sorted((1,2,3,4), reverse=True) # (4,3,2,1) sorted([1,2,3,4], reverse=True) # [4,3,2,1]
dict をソートしたい
key に無名関数を渡すことができます。
a = {0:2, 1:1}
sorted(a.items(), key= lambda kv: kv[1]) # [(1, 1), (0, 2)]
sorted(a.items(), key= lambda kv: kv[0]) # [(0, 2), (1, 1)]
ファイルのopen
open 関数を使います。
with open(file_name, mode="w") as f: f.write("aaa")
みたいにします。mode は色々あります。バイナリにするときは、modeの文字の最後にbを付け加えます。
with を使っていますが、with を使うと、f はブロックが終わったときに、開放されます。
with
先程のwithの仕組みは、__enter__(self)と、__exit__(self, exc_type, exc_value, traceback) というメソッドで実現されています。自分で実装するなら、下記のように出来ます。
class Dummy: def __init__(self): pass def test(self): raise Exception def __enter__(self): print("ENTER") return self def __exit__(self, a, b, c): print("a:{} b:{} c:{}".format(a, b, c)) print("EXIT") return True if __name__ == '__main__': with Dummy() as d: d.test()
下記のようにすると、こんな感じで表示されます。
ENTER a:<class 'Exception'> b: c:<traceback object at 0x7f5c6324e540> EXIT
raise
先程使いましたが、例外を起こします。自分で例外を作る場合は、Exception を継承します。
class MyException(Exception): pass class Dummy: def __init__(self): pass def test(self): raise MyException def __enter__(self): print("ENTER") return self def __exit__(self, a, b, c): print("a:{} b:{} c:{}".format(a, b, c)) print("EXIT") return True if __name__ == '__main__': with Dummy() as d: d.test()
下記のように変わりました。
ENTER a:<class '__main__.MyException'> b: c:<traceback object at 0x7f830fd414c0> EXIT
httpアクセスしたい
requests というモジュールを使います。
res = requests.get(icon_url)
if res.status_code == requests.codes.ok:
with open(icon_file, mode="wb") as f:
f.write(res.content)
動的にモジュールを読み込む
init.py で package_name以下のモジュールを全部読み込ませたい
from inspect import isclass from pkgutil import iter_modules,extend_path from pathlib import Path from importlib import import_module import re # iterate through the modules in the current package package_dir = extend_path(__path__, __name__) for (_, module_name, _) in iter_modules(package_dir): # import the module and iterate through its attributes module = import_module(f"{__name__}.{module_name}") for attribute_name in dir(module): attribute = getattr(module, attribute_name) if isclass(attribute): # Add the class to this package's variables globals()[attribute_name] = attribute
文字列から、improt & オブジェクトの作成
m = importlib.import_module("package_name.module_name", "package_name")
o = getattr(o, "Class")(args)
PILで画像を描く
PILというモジュールで、画像を描くことが出来ます。
時計を描く
from PIL import Image, ImageDraw import math import datetime class Clock: scale_x = 100 scale_y = 100 x = 0 y = 0 l = 0 def __init__(self, scale_xy, xy, l): self.scale_x = scale_xy[0] self.scale_y = scale_xy[1] self.x = xy[0] self.y = xy[1] self.l = l def hour_pos (self, h, m, s): if h == 12: h = 0 h *= 5 h += (m / 12 + s / 60) / 60 l = self.l * 0.7 return self._pos(l, h) def min_pos(self, m, s): l = self.l * 0.9 m += s / 60 return self._pos(l, m) def sec_pos(self, second): return self._pos(self.l, second) def _pos (self, l, t): x = l * math.cos(2 * math.pi / 60 * (15 - t)) y = l * math.sin(2 * math.pi / 60 * (15 - t)) * -1 return [self.x + x, self.y + y] def get_current_hms(self): now = datetime.datetime.now() return [now.hour, now.minute, now.second] def get_current_clock_image(self, hms): im = Image.new('RGB', (self.scale_x, self.scale_y), (0, 0, 0)) draw = ImageDraw.Draw(im) hour_xy = self.hour_pos(hms[0], hms[1], hms[2]) min_xy = self.min_pos(hms[1], hms[2]) sec_xy = self.sec_pos(hms[2]) draw.line((self.x, self.y, hour_xy[0], hour_xy[1]), width=3, fill=(255,255,255)) draw.line((self.x, self.y, min_xy[0], min_xy[1]), width=2) draw.line((self.x, self.y, sec_xy[0], sec_xy[1]), width=2, fill=(255,0,0)) return im if __name__ == '__main__': clock = Clock((110, 110), (50, 50), 100) im = clock.get_current_clock_image((10, 15, 30)) # 10:15:30 im.save("clock.png")
こんな感じで時計が表示できます。

感想
という感じで特にまとまりもなく、使ったコードを書いていった感じですが、特に不満なく書けました。
エラーメッセージが親切だなーと、思いました。typo してるんじゃない?この変数名使いたいんじゃない?とか。
def hoge(i): return ii hoge(1)
とか、やらかすと、下記のような感じで怒られます。
NameError: name 'ii' is not defined. Did you mean: 'i'?
あと、対話的interfaceで、メソッド補完してくれるので、ちょっとした動作を見たいときに便利です。
% python3 >>> a = [1,2,3] >>> a. # .の後にタブを打つ a.append( a.copy() a.extend( a.insert( a.remove( a.sort( a.clear() a.count( a.index( a.pop( a.reverse() >>> a.
なお、ドキュメントは、pydoc3 コマンドで見ることが出来ます。
JavaScriptのcanvasで遊んでいたらPCのパフォーマンスが上がった
はい。嘘です。
正しくは、PCが遅い原因がわかった。でした。顛末は最後に書いていますが、最初は、canvasの使い方から。
canvasの使い方
HTML
HTMLで下記のように書きます。
<canvas id="canvas" width="300" height="170"></canvas>
JavaScript
基本
cotnext
const c = document.getElementById('canvas'); const ctx = c.getContext('2d');
context を取得してから、描画をします。
ctx.beginPath()
beginPath をしないと、最後にいた座標から、線を描き出してしまう場合がありますが、これを呼んでおけば問題ないです。
stroke, fill
storke の場合は、線を描きますが、fillの場合は、中身を塗ります。
- strokeRect, fillRect
- stroke, fill
のように、対になっています。
座標
x= 0, y =0 は、左上になります。 最初に定義したcanvasだと、x=300, y = 170 が右下になります。
線を描く
書きたい場所に移動して、
ctx.moveTo(x, y); ctx.lineTo(x, y); ctx.stroke();
moveToで移動した、x, y から、lineToで指定した、x, y まで線を描画します。
最初に、moveToで、移動して、そこから、lineTo で線の終端をさし、stroke で線を描きます。
四角を描く
strokeRectを使います。
ctx.strokeRect(x, y, xの幅, yの幅)
円を描く
ctx.beginPath()。 ctx.arc( x, y, radius, startAngle, endAngle, counterclockwise) ; ctx.stroke();
radius は半径です。startAngleは開始角度で、endAngleは終了角度。counterclockwiseは、trueなら左回りに線を描きます。
startAngle = 0, endAngle = Math.PI * 2 であれば、真円が描けます。 半円であれば、endAngle = Math.PIです。
ctx.beginPath() をしないと、今いる座標から、円の開始点までの線も描画してしまうので、注意してください。
下向きの半円
ctx.beginPath();
ctx.arc( 10,10, 10, 0, Math.PI, false) ;
ctx.stroke();
下向きの1/4の円
ctx.beginPath();
ctx.arc( 10,10, 10, 0, Math.PI / 2, false) ;
ctx.stroke();
fill で中身を塗りつぶしたい場合は、
ctx.moveTo(10,10);
ctx.arc(10, 10, 10, 0, Math.PI / 2, false) ;
ctx.fill();
fill を使う場合、moveToで移動した座標から、円の開始点から終了点を結んだ部分を塗ります。
なので、下記のようにすると、
ctx.moveTo(90,90);
ctx.arc( 40,40, 50, 0, Math.PI / 2, false) ;
ctx.fill();
外側が塗りつぶされます。

描画したものを消す
clearRect を使います。strokeRectと使い方は同じです。
ctx.clearRect(x, y, xの幅, yの幅);
これで、指定した座標の位置から、x, y の領域を削除します。消す領域ですが、若干多めに取っておいたほうが良いかもしれません。
textを描く
ctx.fillText("テキスト", x, y, 幅);
x, y の座標から幅分の領域に、指定したテキストを描画します。
x, y の位置ですが、テキストの左下が、座標の位置です。
一度描いたものを削除する場合、clearRectで指定するのは、y - フォントサイズ + アルファ くらいを指定するひつようがあります。 y の幅指定も、フォントサイズ+アルファくらいです。
フォントの指定は、下記のように行います。
ctx.font = '9px serif';
canvas の良いところ
プログラマブルに絵を描けるので、配置場所や、スケールも自由に変更できます。
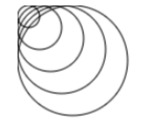
下向きにに複数の円が描かれる。
const c = new MyCircle({id: 'canvas', x: 0, y: 0, scale: 1, direction: false}); c.draw();
上向きに複数の円が描かれる。
const c = new MyCircle({id: 'canvas', x: 0, y: 100, scale: 1, direction: true}); c.draw();
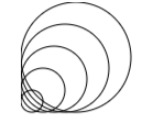
と行った感じにできます。
PCのボトルネックに気づいた理由
アニメーションをしようと思って、setTimeoutで、canvasに描画しまくっていたわけです。
先程のclassに、下記のようなメソッドを追加した感じですね(実際はもっと色々やってた)。
animate (max) { const ctx = this.ctx; max ||= 50; ctx.clearRect(0,0, this.canvas.width, this.canvas.height); const fn = (x) => { x ||= 0; ctx.beginPath(); ctx.arc( this.x + x, this.y + x * (this.direction ? -1 : 1), x, 0, Math.PI * 2, false); ctx.stroke(); if (x < max * this.scale) { setTimeout(() => {fn(x + 1)}, 1); } }; fn(); }
そうすると、描画がクソ重いのが、目に見えてわかるわけですね。
で、たまたま、外部ディスプレイが切れて、ノートPCの方の解像度が変更されたタイミングでスピードがかなり改善されました。
重い原因は何だったのか?
Ubuntuを使っているのですが、解像度の設定と、画面の拡大を指定することが出来ます。下記の赤ラインで引いたところです。

ここを調節していると、思った以上にパフォーマンスが落ちるようです。 Firefoxがまともに動かないレベルで重かったのですが、これを100%にしたら、普通に動きました。
というわけで、せっかくなので、canvasを使ったベンチマークを作りました。反復横飛びの片道で1とカウントしています。 (※遊びでつくっただけです。めっちゃ雑な計測です)
スペックは、下記な感じです。
外部ディスプレイ(3840x2160:100%) ノートPCのディスプレイ(3840x2160:100%)
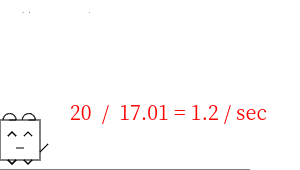
外部ディスプレイ(3840x2160:100%) ノートPCのディスプレイ(1960x1200:100%)

外部ディスプレイ(3840x2160:100%) ノートPCのディスプレイ(3840x2160:125%)

外部ディスプレイ(3840x2160:125%) ノートPCのディスプレイ(3840x2160:125%)

外部ディスプレイ(3840x2160:150%) ノートPCのディスプレイ(3840x2160:125%)
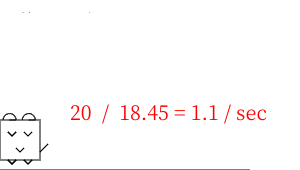
外部ディスプレイ(3840x2160:125%) ノートPCのディスプレイ(1920x1200:100%)
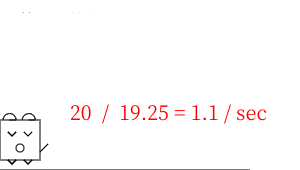
外部ディスプレイ(3840x2160:125%) ノートPCのディスプレイ(3840x2160:100%)
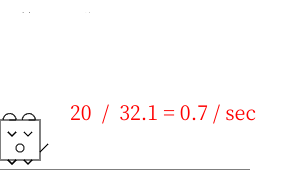
結論
外部ディスプレイとノートPCのディスプレイをいずれかを拡大している場合に一番、パフォーマンスが劣化するようです。
なお、Windoows のSurface Pro 7 Core i7 1.3GHz だと、0.9/sec でした。スマホ(Xiaomi Readmi Note 10 Pro)も0.9/secでした。
IndexedDB の onupgradeneeded の実装例
最近、ブラウザに内蔵されているローカル用のDBのIndexedDBを使ってみました。
DBのスキーマを変更したいようなときに、onupgradeneeded を使いますが、ちょっとした説明と実装例を示します。
なお、動作確認したブラウザは、Chrome 102 です。
IndexedDBでは、DBを開くときにバージョンを渡す
下記の、1というのがバージョンです。
DBOpenRequest = window.indexedDB.open("Sample", 1);
DBがないか、バージョンが変わった場合に呼ばれる upgradeneeded
もともと、バージョンを持っていない場合、もしくは、ブラウザが保持しているバージョンがopenで指定されているものより低い場合に、
upgradeneeded というイベントが呼ばれます。addEventListenerで定義するか、onupgradeneeded に代入するかで実装できます。
下記のように、定義します。
DBOpenRequest.addEventListener("onversionchanged", event => {}); DBOpenRequest.onupgradeneeded = event => {};
event の中身
下記くらい知っていれば良いのではないでしょうか。
| key | value |
|---|---|
| event.oldversion | ブラウザが保持しているバージョン(なければ 0) |
| event.newVersion | openに書かれているバージョン |
| event.target.result | IDBDatabaseオブジェクト |
| event.target.transaction | onupgrade中のトランザクション |
のようなものがあります。
event.oldversion と event.newversion の差分を確認して、必要な変更を当てる必要があります。
実装例
下記のように各バージョンごとに関数定義すると良いのではないかなと思います。
DBOpenRequest.onupgradeneeded = event => { const oldVersion = event.oldVersion; const newVersion = event.newVersion;; const db = event.target.result; const migration = { "1": () => { { // User master const s = db.createObjectStore('user', {keyPath: "nickname"}); s.createIndex("nickname", "nickname", {unique: true}); } { // logs const s = db.createObjectStore("logs", {keyPath: "date"}); s.createIndex("date", "date", {unique: false}); s.createIndex("content", "content", {unique: false}); } }, "2": () => { { // logs (date => loggedDate に変えたくなった) db.deleteObjectStore("logs"); // 消して作り直してます。中身とって、入れ直しとかしたら良いですね。 const s = db.createObjectStore("logs", {keyPath: "date"}); s.createIndex("loggedDate", "date", {unique: false}); s.createIndex("content", "content", {unique: false}); } }, "3": () => { { // logs (titleいるよね) const s = event.target.transaction.objectStore("logs"); // transaction からとってこないとエラーになります s.createIndex("title", "title", {unique: false}); } } } // 最新バージョンになるまで差分を適用 for (let v = oldVersion + 1; v <= newVersion; v++) { if (migration[v]) { migration[v](); } } };
versionchange イベント
これは、試せてないのですが、別のタブとかで開いているときに、片方でDBのバージョンアップが走った場合に、起きるイベントのようです。 勝手にアップデートされる前に、DBに保存すると行った処理を実装するために使うようです。
例として、A, B のタブでSampleというDBを使っている。
そのときに、A で、upgradeが走るときに、B にversionchange イベントが発生するようです。
下記に詳しく載っています。
React事始め
もはや、無数にありそうな話題なので、あまり公に書く意味はないですが、記録しとかないと忘れちゃうので(年齢的な問題で)。
下記の2つのドキュメントを見ながら進めていきますが、主にガイドの方の内容になります。 ja.reactjs.org ja.reactjs.org
Vue.jsはちょっと触ったことありますが、Reactは初めて触ります。
その前に、nvm のインストール
PC変えてから、まともにnode使ってなかったので、nvmからインストール
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash source ~/.zshrc nvm install --lts 16 nvm use 16
nvm以外にも色々あるようですね。
開発準備
ここから、チュートリアルと主にガイドの内容を元に進めます。
npx create-react-app my-app rm src/* touch src/index.css
src/index.js に下記の内容を記載
import React from 'react'; import ReactDOM from 'react-dom/client'; import './index.css';
これで、下記で、http://localhost:3000 がブラウザで開きます。
npm start
ポートを変更したい場合は、
echo "PORT=3001" > .env
のようにして、.env内で、PORTを指定してやればよいです。
Hello, world! を表示する
index.js に下記を追加します。
const root = ReactDOM.createRoot(document.getElementById('root')); const element = (<h1>Hello, world!</h1>); root.render(element);
下記が表示されました。めでたし。

JXS
先程書いた、<h1>Hello, world!</h1> ですが、JSXというものです。JSXを使う理由は下記のように説明されています。
表示のためのロジックは、イベントへの応答や経時的な状態の変化、画面表示のためのデータを準備する方法といった、他の UI ロジックと本質的に結合したものであり、React はその事実を受け入れます。 マークアップとロジックを別々のファイルに書いて人為的に技術を分離するのではなく、React はマークアップとロジックを両方含む疎結合の「コンポーネント」という単位を用いて関心を分離します。後のセクションでコンポーネントについては改めて詳しく紹介しますが、現時点で JavaScript にマークアップを書くことが気にくわない場合、こちらの議論で考えが改まるかもしれません。 React で JSX を使うことは必須ではありませんが、ほとんどの人は JavaScript コード中で UI を扱う際に、JSX を見た目に有用なものだと感じています。また、JSX があるために React は有用なエラーや警告をより多く表示することができます。
なお、タグの中身がない場合(imgタグなど)は、XMLのような感じで、記述します。
<img src="/path/to/file" />
また、下記のようにJXS内で改行しても問題ありません。
const element = (<h1> Hello, {user.name}! </h1> );
JSX内で、JavaScriptを実行する
JSX内では、{} の中に JavaScriptの処理を書くことができます。
const user = { name: "ktat" }; const element = (<h1>Hello, {user.name}!</h1>);
このように変数を参照するだけでも、下記のように、関数を呼び出すこともできます。
function displayName (u) { return u.name; } const user = { name: "ktat" }; const element = (<h1>Hello, {displayName(user)}!</h1>); root.render(element);

{} をタグの属性の値の指定に利用する
<div class="name"> のname を設定したい場合です。
const user = { name: "ktat" }; const element = (<h1 class="{user.name}">Hello, {user.name}!</h1>); root.render(element);
上記のようにしたら...と思いますが、これだと、そのままの内容がクラス名となってしまいます。
![]()
クォートが不要です。下記のようにしましょう。
root.render(<h1 class={user.name}>Hello, {user.name}!</h1>);
![]()
無事に、クラスが設定できました。
と、思いましたが、class ではなくて、className と指定するのが、正しいようです。consoleに下記のメッセージが出ました。
react-dom.development.js:86 Warning: Invalid DOM property `class`. Did you mean `className`?
at h1
なお、クラス名を複数渡したい場合は...、JavaScriptがかけるので、どのようにでもできます。
テンプレートリテラル
className={`${var1} ${var2}`}
関数(スペースで文字列を join する、classNamesという関数を作る)
className={classNames(var1, var2)}
文字列をHTMLとして使いたい
下記のようにすると、
let s = "<"; root.render(<div>{s}</div>);
< が表示されるのではなくて、< がそのまま表示されます。セキュリティのためだと思いますが、あえて、HTMLとして評価したいような場合は、
dangerouslySetInnerHTMLを使います。
root.render(<span dangerouslySetInnerHTML={{__html: s}}></span>);
インストールが必要ですが、html-react-parser も使えます。
const htmlParse = require('html-react-parser');
しておいて、下記のように使えば、HTMLとして解釈されます。
let s = "<"; root.render(<div>{ htmlParse(s) }</div>);
JSXとは?
JSXはオブジェクト表現であり、JXSの返すものをReact要素と呼びます。詳しくは、こちらを。
const element = (<h1>Hello, world!</h1>)
は、
const element = React.createElement( 'h1', 'Hello, world!' );
の呼び出しにコンパイルされ、結果として、
const element = { type: 'h1', props: { children: 'Hello, world!' } };
下記のようなオブジェクトになります。これをReact要素と呼びます。
{}で書いたJavaScriptも評価された結果のオブジェクトになります。
レンダーされた要素を更新する
React要素は一度要素を作成すると、子要素や属性を変更することができません。 前述の通り、変数や関数を指定したとしても、すでに評価済みなので、renderの後に、こんなことをしても何も起きません。
root.render(element); setTimeout(() => { user.name = "hogehoge!"; root.render(element) }, 1000)
renderの後に、下記のように新しくReact要素を作って、renderすれば、更新はできます。
root.render(element); setTimeout(() => { user.name = "hogehoge"; const element2 = (<h1 className={user.name}> Hello, {displayName(user)}! </h1> ); root.render(element2); }, 1000);
1秒後に、ktat が、hogehoge に変わるようになります。
しかし、あまりにアレすぎるので、React要素を作るところを関数化してみます(※いずれにしても良い例ではありません)。
React要素を作る部分を関数化する
これで、1秒ごとに、切り替わって、何回目かも表示されるようになりました。
const root = ReactDOM.createRoot(document.getElementById('root')); let n = 0; function hello() { const userName = n++ % 2 == 0 ? 'ktat' : 'world'; const element = (<h1> Hello, {userName}!<br /> (count: {n}) </h1> ); root.render(element); } setInterval(hello, 1000);
※ root.render を何回も呼び出していますが、普通は、一回しか呼び出さないです。state付きコンポーネントでそれを実現します。と、書いてますね。
なお、Reactでは(というか、Vueとかもですが)、必要な部分のみが更新されるので、上記の例だと、world,ktat の部分、と、count: の右の数字の部分。動的に変更される部分以外は、変更されません。Developer tool でみるとわかります。
コンポーネントとprops
JavaScriptのfunctionを大文字で始めると、コンポーネントとなります。
function Hello(props) { return (<h1> Hello, {props.name}! </h1> ); }
これは、JSXで下記のように使えます。
const element = <Hello name="ktat" />;
root.render(element);
することで、以前と同様、Hello, ktat! が表示されます。
コンポーネント化したことで、下記のように名前を変えて、同じものを複数表示するのも簡単です。
const element = ( <div> <Hello name="ktat" /> <Hello name="world" /> <Hello name="Internet" /> </div> ); root.render(element);

なお、propsは読み取り専用なので、変更してはいけません。
※最初、下記のように記載したのですが、エラーになりました。理由は追っていません。
const element = ( <Hello name="ktat" /> <Hello name="world" /> <Hello name="Internet" /> );
state とライフサイクル を使う
state を使うためには、関数コンポーネントをクラスに変更する必要があります。
前述の、
function Hello(props) { return (<h1> Hello, {props.name}! </h1> ); }
こちらは、下記のように書いても等価となりますが、下記の形式で記載する必要があります。
class Hello extends React.Component { render() { return <h1>Hello, {this.props.name}</h1>; } }
これに、state を導入します。
class Hello extends React.Component { constructor(props) { super(props); this.state = {date: new Date()}; } render() { return <h1>Hello, {this.props.name} at {this.state.date.toLocaleTimeString()}</h1>; } }
このままだと、時間が表示されるだけで、最初に表示されたままで変わりません。
マウント・アンマウント時にメソッドを実行する
Reactでは、DOMが描画されることをマウントといい、DOMが削除されるときをアンマウントといいます。
コンポーネントクラスにcompnentDidMountというメソッドを追加すると、マウントした後(DOMがレンダーされた後)に実行できるようになります。
また、componentWillUnmountというメソッドを追加することで、コンポーネントがアンマウントされて破棄される直前に呼び出されるようになります。
これを利用して、マウント時にtimerをセット、アンマウント前にtimerをクリアする(現在の例ではアンマウントするところがないので、ここでは特に不要といえば不要です)ようにします。 追加するものは、下記になります。
componentDidMount() { this.timerID = setInterval( () => this.setDate(), 1000 ); } componentWillUnmount() { clearInterval(this.timerID); }
componentDidMount内で呼び出されているsetDateは、下記のようなもので、this.setStateを呼び出しています。これによって、Reactがstateが変更されたことがわかり、renderを再呼び出しします。
setDate() { this.setState({ date: new Date() }); }
これで、時間が動的に変わるようになりました。全体のコードは、下記のようになります。
import React from 'react'; import ReactDOM from 'react-dom/client'; import './index.css'; const root = ReactDOM.createRoot(document.getElementById('root')); class Hello extends React.Component { constructor(props) { super(props); this.state = { date: new Date() }; } componentDidMount() { this.timerID = setInterval( () => this.setDate(), 1000 ); } componentWillUnmount() { clearInterval(this.timerID); } setDate() { this.setState({ date: new Date() }); } render() { return <h1>Hello, {this.props.name} at {this.state.date.toLocaleTimeString()}</h1>; } } const element = ( <div> <Hello name="ktat" /> <Hello name="world" /> <Hello name="Internet" /> </div> ); root.render(element);
注意事項
setStateを必ず使う
this.state = { date: new Date() };
のように最初に定義しているのだから、setDate() でも、同様にすれば良いと思うかもしれませんが、setState を利用しないと、再Renderはされません。なので、必ず、stateを更新する際は、setStateを使います。
this.state に直接代入できるのは、constructorのみです。
this.props と this.state は非同期に更新される
ここの例のままですが、下記のようにするのは、NGで、
// Wrong this.setState({ counter: this.state.counter + this.props.increment, });
下記のように、setStateに関数を渡す形にしないといけません。
// Correct this.setState((state, props) => ({ counter: state.counter + props.increment }));
setState での更新はマージされる
this.state = { a: 1, b: 2, c: {d: 1} };
のように、constructorで定義したとして、
setState(c:{e: 2});
のように更新すると、下記のように変更されます。
{ a: 1, b: 2, c: {e: 2} }
変更しなかったa,bは、そのままですが、変更されたc はまるっと変更({d: 1} => {e: 2})されます。
イベント処理
下記のように書くことで、aタグをクリックした際に、alertが表示されるようになります。
function clickAtag() { alert(1); } const element = ( <div> <a href="https://exapmle.com/" onClick={clickAtag}>click</a> </div> ); root.render(element);
このままだと、https://example.com/に移動しますが、移動したくない場合は、falseを返すのではなくて、preventDefaultを使います。
function clickAtag(e) { e.preventDefault(); alert(1); }
ここで使われている、eは、合成イベントと呼ばれるもので、ブラウザの互換性は気にしなくて良いとのことです。
Reactでは、addEventListenerを使うのではなくて、最初に要素を作成する際に、リスナを指定するとのことです。
コンポーネントクラスの中に書く
その場合は、下記のようにします。先に使った例のものに、入れます。
render() { return (<div> <h1>Hello, {this.props.name} at {this.state.date.toLocaleTimeString()}</h1> <a href="https://exapmle.com/" onClick={this.clickAtag}>click</a> </div>); } clickAtag(e) { e.preventDefault(); alert(1); }
イベント処理でstateを更新する
特に難しいことはないはずですね。今回、componentDidMount とかは不要なので削除しています。
class Hello extends React.Component { constructor(props) { super(props); this.state = { date: new Date() }; } clickAtag(e) { e.preventDefault(); this.setState({ date: new Date() }); } render() { return (<div> <h1>Hello, {this.props.name} at {this.state.date.toLocaleTimeString()}</h1> <a href="https://exapmle.com/" onClick={this.clickAtag}>click</a> </div>); } }
ですが、エラーになります。clickAtag内で、this が使えません。
下記のようにする必要があります。
<a href="https://exapmle.com/" onClick={this.clickAtag.bind(this)}>click</a>
これで、クリックするたびに時刻が変わるようになりました。
条件付きレンダー
これは、普通にif とか使ってるだけなので、特別なことはなさそうです。
例えば、時刻の末尾が0と5のときだけ、赤くしたいなら、
class Hello extends React.Component { constructor(props) { super(props); this.state = { date: new Date() }; } clickAtag(e) { e.preventDefault(); this.setState({ date: new Date() }); } render() { let t = this.state.date.toLocaleTimeString(); let c = t.match(/[05]$/) ? "color: red" : "color: black"; return (<div> <h1>Hello, {this.props.name} at {t}</h1> <a style={{color: c}} href="https://exapmle.com/" onClick={this.clickAtag.bind(this)}>click</a> </div>); } }
※ styleについても、全体を文字列として"color: red" のようには渡せないようです。
レンダーさせたくない
なお、rednerさせたくない場合は、nullを返すようにします。
以下のようにすると、0秒と5秒のときにクリックする(か、最初のrender時が0秒か5秒なら)と、コンポーネントはなくなってしまいます。
if (t.match(/[05]$/)) { return null; }
インラインの条件
下記のように、JSX内に条件を書くこともできます。
render() { let t = this.state.date.toLocaleTimeString(); return (<div> <h1>Hello, {this.props.name} at {t}</h1> <a style={{color: t.match(/[05]$/) ? "red" : "black" }} href="https://exapmle.com/" onClick={this.clickAtag.bind(this)}>click</a> </div>); } }
&& や || も使えますが、falseな場合でも、条件の左の結果自体は、レンダリングされますので注意してください。
let t = this.state.date.toLocaleTimeString(); let n = 0 return (<div> <h1>Hello, {this.props.name} at {t}</h1> { n && "not 0"} </div>); }
0が表示されてしまいます。
true/falseであれば、renderingされないので、結果が欲しくなければ、下記のようにtrue/falseが返るようにしてやればよいです。
let t = this.state.date.toLocaleTimeString(); let n = 0 return (<div> <h1>Hello, {this.props.name} at {t}</h1> { n !== 0 && "not 0"} </div>); }
一度変数に入れる
以下のように、一度変数に入れてもOKです。
let term = 1; let component = ""; if (term === 1) { component = <h1>aaa</h1> } return (<div>{component}</div>)
リストとkey
リストを使って、同じコンポーネントを複数表示させましょう。
render() { let t = this.state.date.toLocaleTimeString(); let names = ["World", "Internet"] let element = names.map((name) => <h1>Hello, {name}</h1>) return (<div>{element}</div>); }
ちゃんと表示されますが、consoleにwarningがでます。
Warning: Each child in a list should have a unique "key" prop.
素直にしたがって、keyとして同じものを与えてみます。
render() { let t = this.state.date.toLocaleTimeString(); let names = ["World", "Internet"] let element = names.map((name) => <h1 key={name}>Hello, {name}</h1>) return (<div>{element}</div>); }
これで、warningは消えます。
keyは要素の変更、追加、削除等をReactが識別ために使うということのようで、ユニークなID(兄弟要素の中でユニーク。グローバルでユニークでなくて良い)を使うべきです(別にHTMLのタグ内のidとかになるわけではないので、あくまで内部で管理されているはず)。
具体的にどう使うかは、まだ不明。
フォーム
フォームは、ユーザーが変更可能なものなので、そのままだとReactの制御下にならないのですが、valueにstateを入れることで、制御されたコンポーネントとすることができます。
class Hello extends React.Component { constructor(props) { super(props); this.state = { nValue: "", rValue: "", tValue: "" }; } handleText(e) { this.setState({nValue: e.target.value}); } handleTextArea(e) { this.setState({tValue: e.target.value}); } handleRadio(e) { console.log(e); this.setState({rValue: e.target.value}); } render() { return (<div> <form> <input type="text" name="n" value={this.state.nValue} onChange={this.handleText.bind(this)} /><br /> <ul> <li><input type="radio" name="r" value="1" onChange={this.handleRadio.bind(this)} />1</li> <li><input type="radio" name="r" value="2" onChange={this.handleRadio.bind(this)} />2</li> <li><input type="radio" name="r" value="3" onChange={this.handleRadio.bind(this)} />3</li> <li><input type="radio" name="r" value="4" onChange={this.handleRadio.bind(this)} />4</li> </ul> <textarea value={this.state.tValue} onChange={this.handleTextArea.bind(this)} /><br /> nValue: {this.state.nValue}<br /> rValue: {this.state.rValue}<br /> </form> </div>); } }
このようにすると、入力されたテキストや、選択された値が、下記の部分に動的に入ることになります。
nValue: {this.state.nValue}<br /> rValue: {this.state.rValue} tValue: {this.state.tValue}
他のformタグや複雑な使い方については、ドキュメントを読みましょう(そろそろ疲れてきた)
ちなみに、bind(this)をいっぱい書いてますが、constructorで下記のようにすれば、
constructor(props) { super(props); this.state = { nValue: "", rValue: "", tValue: "" }; this.handleRadio = this.handleRadio.bind(this); // こう書いておく }
としておけば、下記のように書くだけでOKです(じゃぁ、そう書けよっていう)。
{this.handleRadio}
stateの共有(リフトアップ)
説明は割愛していますが、state は各コンポーネントで独立していますので、一方で変更したものは、他方ではわかりません。 ですが、共有したいようなときもあるので、その場合は、以下のようにします。
2つのコンポーネントで入力されたものを別のコンポーネントで足し合わせるといったものとか。
そろそろ、疲れてきて、ドキュメントの通りにやっていないんですが、下記な感じでできますね。良いのかな。
lass Hello extends React.Component { constructor(props) { super(props); this.name = props.name this.state = { nValue: ""}; } handleText(e) { this.setState({nValue: e.target.value}); this.props.state.v[this.name] = e.target.value; this.props.change(); } render() { return ( <div> <form> <input type="text" name="n" value={this.state.nValue} onChange={this.handleText.bind(this)} /><br /> nValue: {this.state.nValue}<br /> a: {this.props.state.v.a}<br /> b: {this.props.state.v.b}<br /> </form> </div> ); } } class HelloSum extends React.Component { constructor(props) { super(props); this.state = { v: {a: "", b: ""} }; } changeState() { this.setState({}); } render() { return (<div> <Hello name="a" state={this.state} change={this.changeState.bind(this)} /> <Hello name="b" state={this.state} change={this.changeState.bind(this)} /> mixed: {this.state.v.a + this.state.v.b} </div>); } } const element = ( <div> <HelloSum name="" /> </div> ); root.render(element);
- HelloSumコンポーネントから、Helloに対して、自身のstateと、setStateするだけの関数をpropsとして渡す。
- Helloでは、textが変更されたら、
handleText内で、this.props.stateを更新し、this.props.change()を呼び出して、空のsetState()をすることで、Renderする
ドキュメントだと、こんな感じな気がする。
class Hello extends React.Component { constructor(props) { super(props); this.name = props.name this.state = { nValue: "" }; } handleText(e) { this.setState({nValue: e.target.value}); this.props.change(this.name, e.target.value); } render() { return ( <div> <form> <input type="text" name="n" value={this.state.nValue} onChange={this.handleText.bind(this)} /><br /> nValue: {this.state.nValue}<br /> a: {this.props.a}<br /> b: {this.props.b} </form> </div> ); } } class HelloSum extends React.Component { constructor(props) { super(props); this.state = { v: {a: "", b: ""} }; } changeState(name, v) { let d = this.state; d.v[name] = v this.setState(d); } render() { return (<div> <Hello name="a" a={this.state.v.a} b={this.state.v.b} change={this.changeState.bind(this)} /> <Hello name="b" a={this.state.v.a} b={this.state.v.b} change={this.changeState.bind(this)} /> mixed: {this.state.v.a + this.state.v.b} </div>); } } const element = ( <div> <HelloSum name="" /> </div> ); root.render(element);
- props として、親コンポーネントのstateと、状態を変更するための関数を渡す
- 子コンポーネントでは、propsからもらっている値を表示しておく
- 子コンポーネントから入力されたら、親から渡された関数を呼んで、setStateが呼ばれて更新される
コンポジション vs 継承
継承は不要ということのようです。
React の流儀
後は、読み物なので、良いでしょう。
終わり
試しつつ、Blog書きながらというところもありますが、5-6時間かかったかな。疲れた。
参照
途中で言及していた、classNameとか、styleのJSXの記法とかは、下記を見ておく必要がありそうですね。
UXデザインの法則を読んで感銘を受けたのでまとめた
- 本の概要
- 1. ヤコブの法則
- 2. フィッツの法則
- 3. ヒックの法則
- 4. ミラーの法則
- 5. ポステルの法則
- 6. ピークエンドの法則
- 7. 美的ユーザビリティ効果
- 8. フォン・レストフル効果
- 9. テスラーの法則
- 10. ドハティのしきい値
- 終わり
本の概要
会社の人に勧められて読んでみたところ、とても良かったです。 行動心理学の側面でユーザーにとって良いUXについて書かれています。

150ページ程度の本ですが、10の法則について、端的にまとまっており、事例もあるため、非常にわかりやすく、読んでいて納得感があります。
各法則を簡単に紹介したいと思います。
1. ヤコブの法則
ヤコブといえば、ユーザービリティエンジニア原論ですかね。 この法則は、「慣れ親しんだ見た目であれば同じように動くと、ユーザーは期待する」というものです。
どんな話かといえば、ドアノブのついたドアが、引き戸だったら、戸惑いますよね。そういう話です。 ドアノブがあれば、回してから、押すなり引くなりするのを想定するのが普通です。
新しく何かを作る場合でも、世の中にあるものを踏襲したほうがユーザーはわかりやすいです。 また、既存のものを大きく変えたい場合は、古いものも使えるようにしておかないと、ユーザーは離れていってしまう。
GoogleとかAWSとかコンソールのUIをちょいちょい変えますが、旧バージョンを使えるようにしていますね。
 ↑ AWSのEC2のコンソール。UIを切り替えることができます。
↑ AWSのEC2のコンソール。UIを切り替えることができます。
2. フィッツの法則
「クリックさせたいとか、タップさせたいとかいう、ターゲットについて、十分に大きく、他のターゲットと十分に離れていて、簡単に届かないといけない」というものです。
スマホのソフトウェアキーボードとか、キー同士が十分に離れてないと押し間違えてしまいます。ただ、離れすぎていても使い勝手は悪いです。 OKとキャンセルが近接していて、十分に間隔が開いていなければ押し間違えてしまいます。よく使うターゲットがスマホの右上とか左上とかにあると、押しにくい...とかそういうことですね。
ラベルとフォームが並んでいるときに、ラベルをタップしたら、フォームにフォーカスが当たるというのも、この法則に則っています。
3. ヒックの法則
「意思決定をさせたいなら選択肢は少ないほうが良い」というものです。
例えば、有料プランが10種類もあると、ユーザーは何を選択したらいいか比較検討するものが多すぎるし、意思決定がなかなかできない。 なので、たいていサービスで有料プランは3つ程度に抑えられているし、さらに、おすすめのプランみたいな表示をして、ユーザーが意思決定にかける負担を減らしています。


↑ Google Workspace の pricing のページ
もし複雑な意思決定が必要だったとしても、細かく分解して、それぞれの意思決定を小さくすればユーザーの負荷も減ります。
人間も、コンピュータ同様ワーキングメモリがあって、情報が多すぎるとワーキングメモリから溢れてしまう。 そうすると、見るべき情報が落ちてしまったり、イライラしてやめてしまったりする。
タスクいっぱい詰め込んでると、見落としが多くなったりしますね。わかりみが激しい...。
意思決定だけではなくて、ナビゲーションが多すぎるメニューや、機能が多すぎるリモコンなど、ユーザーが選択するのに、必要な情報が多すぎると、処理できなくなって諦めてしまう。
ただ、逆に単純化しすぎて、アイコンだけみたいになってしまっても、アイコンの意味を推測したりするのに負荷がかかっても良くないので、アイコンはラベルと一緒にしたほうが良いとか紹介されていました。
4. ミラーの法則
「人間が短期的に記憶できるのは、7(±2)まで」というものです。
これは誤解が多いというように紹介されていますが、7(±2)の文字数にしないといけないのではなく、ある程度の塊にチャンク化すれば良いということです。 携帯電話番号は11桁ですが、3-4-4の桁数で3つにチャンク化されているので、読みやすいし、覚えやすい。
チャンク自体の大きさが…という話でもなく、例えば、長い文章をだらだら書くのではなく、階層化や構造化する。 ちゃんと分類して、他と区別が付くようなチャンクにするということが重要とのことです。
5. ポステルの法則
「入力については寛容に扱い、出力については厳密に扱うべき」というものです。
住所は全角のみで入力しないといけない...というようなサイトがありますが、典型的な悪い例です。 全角・半角だろうが入力はどちらも許して、内部で正規化してやればいいだけです。
また、昨今ではいろいろなデバイスからアクセスされることがあります。PCだけしか、スマホだけとか、じゃなくて、両方から入力できるようにするほうが良いし、なんなら、ウエアラブルデバイスとかTVとかゲーム機とかVR機器から入力される場合もありえます。
サービスによっては、色んな言語を使う人からアクセスされる場合もありますので、言語によって単語の長さも異なります。 それに合わせてメニューを多少削ったりする必要もあるということにも言及されています。
6. ピークエンドの法則
「人間の記憶に残るのは、感情のピークのとき(ポジティブでもネガティブでも)と、最後に近いところ。また、人はネガティブな感情のところの方を思い出しやすい」というものです。
客観的、全体を平均的に見れば「良い」と判断できる事象でも、最後にネガティブな感情になると、それが非常に強く残るというものです。 遊園地に行って楽しかったけど、後半は雨に振られてびしょぬれになって散々だったとか。楽しかった記憶よりも、後半の悲惨な記憶のほうが残りやすい、みたいな感じです。
事例として、MailChimpというサービスでは、ユーザーがメールを初めて送ったらハイファイブする画像とメッセージがでるそうです(この話はProduct Led Growth)でも例にあがっていました。 Slackとかでも、all unread の未読をなくしたら、楽しげな画像がでたりしますね。


↑ Slackの all unread を全部読んだときの表示(The world is oyster については、こちらに解説がありました)
twitterのクジラ、Githubの404、Googleで検索結果が見つからなかった時に表示しているページがちょっと楽しい感じになっているのは、ネガティブピークを、ネガティブなもので無くす役目があるようです。

↑ Googleで検索結果が見つからなかった時のページ(ちなみにクリックするとなにか釣れます)。
7. 美的ユーザビリティ効果
「デザインが美しいと、使い勝手が良いと思ってしまう」というものです。
明らかに使い勝手がわるいUIでも、デザインが美しいと、使いやすいと思ってしまう。
もし、本当にユーザビリティだけをテストをしたいなら、簡素なデザインでテストしたほうが良さそうです。
でも、本番ではデザインが美しければ、ユーザビリティの不備をごまかすことができるかもしれません。
8. フォン・レストフル効果
「似たものが並んでいると、その中で異なるものが記憶に残りやすい」というものです。 逆に言うと、全部同じような感じだと記憶には残らないということですかね。
重要なアクションや情報は、色を変えるとかコントラストを変えるなどで注意を引くようにすると良いというものです。
フィッツの法則のところにあった、料金のところで、目立たせるというのは、これにも関連しそうですね。
ただ、コントラストの差も多用しすぎると逆に目立たなくなります。また、色覚障害の人(日本国内で320万人、男性は20人に1人が色覚に障害があるとのことです)にも考慮しないと、色を変えても一部の人には意味がないことになりそうです。
9. テスラーの法則
「どんなシステムでも、それ以上複雑さを減らすことができない、複雑性保存の法則というものがある」というものです。 本に挙げられている例ですと、メールを送る場合、From, To, Subject, Body というのが必須の複雑性としてあります。
この複雑性の負荷をシステムかユーザーが請け負う必要があります。
- Fromは、ユーザー自身ですので自動的にシステムで決定できます。
- Toは、ユーザーが入力することができますが、部分入力で推測等はシステムでできます。
- Subject, Body は、ユーザーが書く必要があります(Bodyは、Gmail だと、アシストしてくれたりしますね)。
ECサイトの住所入力で、郵便番号を入力すれば住所を補完してくれるのも、システムがユーザーの代わりに請け負っているということです。
自分たちの作るシステムの複雑性を考慮して、システムに任せることができるなら、できる限りシステムにやらせるようにすれば、システムの複雑性に対するユーザーの負荷は減りますね。
10. ドハティのしきい値
「0.4秒未満でレスポンスを返すべき」というものです。
- 0.1秒未満の遅延 ... ユーザーは気づかない
- 0.1-0.3秒の遅延 ... ユーザーが気づき始める
- 1秒以上の遅延 ... ユーザーは他のことを考え始める
最近のコンテンツ量の増大(昔(20年以上前)は100KB未満にしろとか書いてたな)とか、スマホのレイテンシとかを考えると、すべてを0.4秒未満に返すことはなかなか難しいと思いますが、
- 0.4秒未満でガワだけ出しておいて、画像等を遅延ローディングする
- ロード中を表す画像を表示する
- プログレスバーを表示する(不正確でもOK)
といったことを行うことで、ユーザーに速くレスポンスを返す、動いているということを伝える、ということが重要とのことです。 プログレスバーは不正確でも良いとありますが、ファイルを大量コピーするときのプログレスバーは明らかに嘘やろ...という気分にしかなりませんが。
一方で面白いことが書いてありました。人が想像するよりも、あまりに速すぎると、逆にちゃんと動いているのか疑ってしまう、ということもあるようです。 例えば、100GBのファイルのアップロードに1秒かからなかったら、嘘でしょと思ってしまうと言った感じです(まぁ、これは嘘でしょが正しいでしょう)。
例えば、1000人のユーザーにメールを送るという処理が、0.1秒で終わったら、本当に終わってんのかな?って思う人もいるかもしれませんね。
終わり
というわけで、10の法則を簡単に説明してみました。実際の書籍には、論拠とかが書いてあったり、例がもっと豊富にあるので、ちゃんと読んでもらったほうが絶対良いと思います。法則以外にデザインシステムの話等にも触れています。
なんらかのサービスや、システムに関わるなら必読書じゃないかな、と思いました。
OpenSCADでDIY(家具とか)の設計をする
別に技術系の話ではないのですが、こっちの素養がある方には馴染みやすいツールじゃないかなと思って、こっちに書いてます。
OpenSCADって?
OpenSCADは、3D CADモデラーです。
僕はUbuntuで使っていますが、macOSでも、Windowsでも使えます。
どういうふうに使うのか?
僕は他のCADを使ったことはありませんので、まったく比較とかはできませんが、GUIでぐりぐり動かすような感じのものでは、全く無いです。
プログラム的な感じで、形を定義して、配置して、組み合わせた結果を図として表示してくれるものです。
この記事で書かれていること
今回紹介する機能は、OpenSCADのほんの一部の機能です。あくまでDIYで家具類を作るための最低限の紹介になります。
複雑な構造や、3Dプリンターとかの話は範囲外なので、期待した方は残念ながら対象外です。
百聞は一見にしかず
ということで、実際のコードと図を例示します。これ、最初の頃によくわからずに作ったものなので、愚直にものを定義していっちゃってますが、後で直します。
// left side
translate([0,0,0]) {
cube([23,2.7,44]);
}
// right side
translate([0,25.7,0]) {
cube([23,2.7,44]);
}
// back
translate([0,2.7,6.3]) {
cube([2.7,23,35]);
}
// front
translate([23,5.2,2.4]) {
cube([2.7,18,39]);
}
// front left
translate([23,0,2.4]) {
cube([2.7,5.2,39]);
}
// front right
translate([23,23.2,2.4]) {
cube([2.7,5.2,39]);
}
// front botttom
translate([23,-0.25,-0.25]) {
cube([2.7,29,2.7]);
}
// front top
translate([23,-0.25,41.4]) {
cube([2.7,29,2.7]);
}
// top
translate([0,2.7,41.3]) {
cube([23,23,2.7]);
}
// bottom
translate([0,2.7,3.6]) {
cube([23,23,2.7]);
}
上記のコードで、下記のような図ができあがります。

なお、この画像ではわかりませんが、底面に隙間を作っています。キャスターを取り付けるために空けています。
簡単に説明
cube というのは、直方体を定義できます。cube([23,2.7,44]) と書かれているのは、x: 23cm, y: 2.7cm, z: 44cm という意味で使っていますが、単位は、僕が勝手にそう決めているだけなので、230にして、mm としても別に問題ないです。
translateは、その中に書かれているものをどこに配置するか、translate([0,0,0])であれば、中心から配置しますし。translate([0,25,7,0]) であれば、y方向に25.7の位置に配置するということです。
なお、このコードだと、x: 奥行き、y: 幅、z: 高さ という感じになっています(z は大丈夫でしょうが、x,y は、気分で作ると、毎回ちがってたりします)。
moduleを使うべき
先程のものでも、ちゃんと図ができあがるのですが、同じcubeの定義がいくつもあるのが、わかるかと思います。全然いけてません。
moduleとして定義すると良いです。
module side_wall() { // 2枚
cube([23,2.7,44]);
}
module front_top_bottom() { // 2枚
cube([2.7,29,2.7]);
}
module top_bottom() { // 2枚
cube([23,23,2.7]);
}
module front_side() { // 2枚
cube([2.7,5.2,39]);
}
module back() { // 1枚
cube([2.7,23,35]);
}
module front() { // 1枚
cube([2.7,18,39]);
}
// left side
translate([0,0,0]) {
side_wall();
}
// right side
translate([0,25.7,0]) {
side_wall();
}
// back
translate([0,2.7,6.3]) {
back();
}
// front
translate([23,5.2,2.4]) {
front();
}
// front left
translate([23,0,2.4]) {
front_side();
}
// front right
translate([23,23.2,2.4]) {
front_side();
}
// front botttom
translate([23,-0.25,-0.25]) {
front_top_bottom();
}
// front top
translate([23,-0.25,41.4]) {
front_top_bottom();
}
// top
translate([0,2.7,41.3]) {
top_bottom();
}
// bottom
translate([0,2.7,3.6]) {
top_bottom();
}
同じサイズのものは、間違いなくmoduleにしたほうが良いですが、一つしか使わないものも、moduleにしたほうが良いです。
なぜなら、木材を注文する時に、moduleを見て買えば良いからです。なので、コメントに 2枚 とか書いておくと、良いですね。
for を使う
もう少し改善できます。for ループを使うことができます(moduleは同じなので省略します)。
// left/right side
for (i = [0,25.7]) {
translate([0,i,0]) {
side_wall();
}
}
// back
translate([0,2.7,6.3]) {
back();
}
// front
translate([23,5.2,2.4]) {
front();
}
// front left/right
for (i = [0,23.2]) {
translate([23,i,2.4]) {
front_side();
}
}
// front botttom/top
for (i = [-0.25, 41.4]) {
translate([23,-0.25,i]) {
front_top_bottom();
}
}
// top/bottom
for (i = [41.3,3.6]) {
translate([0,2.7,i]) {
top_bottom();
}
}
色を付ける
module に color を付けることもできます。
module side_wall() {
color("red")
cube([23,2.7,44]);
}

こんな感じで赤くなりました。
変数を使う
発注するときに面倒なので、あんまり変数を使いすぎると良くないかもしれませんが。
こんな感じで、height という変数を定義してやると、もともと高さ44cmのを作ろうと思ってたけど、もう少し高くしよう、と思ったときでも、簡単に変更できます。
height = 60;
module side_wall() {
color("red")
cube([23,2.7,height]);
}
module front_top_bottom() {
cube([2.7,29,2.7]);
}
module top_bottom() {
cube([23,23,2.7]);
}
module front_side() {
cube([2.7,5.2,height - 5]);
}
module back() {
cube([2.7,23,height - 9]);
}
module front() {
cube([2.7,18,height - 5]);
}
// left/right side
for (i = [0,25.7]) {
translate([0,i,0]) {
side_wall();
}
}
// back
translate([0,2.7,6.3]) {
back();
}
// front
translate([23,5.2,2.4]) {
front();
}
// front left/right
for (i = [0,23.2]) {
translate([23,i,2.4]) {
front_side();
}
}
// front botttom/top
for (i = [-0.25, height - 2.6]) {
translate([23,-0.25,i]) {
front_top_bottom();
}
}
// top/bottom
for (i = [height - 2.7,3.6]) {
translate([0,2.7,i]) {
top_bottom();
}
}
鉄のシェルフブラケットを表してみる
箱から離れまして、よく、壁に取り付ける「シェルフブラケット」と呼ばれるものがあるんですが、下記のようなものです。
下記のようなmoduleで定義できます。
module bracketInner(){
cube([21,1.2,7]);
}
module bracket() {
color("black")
difference () {
cube([22.5,1,57]);
for (i = [0.8:8:56]) {
translate([0.5,-0.1,i]) bracketInner();
}
}
}
cube で大きな、板を作って、for で回して、angleInnerを、difference(2番目以降の子ノードを減算する)を使って抜いています(angleInnerを少し大きくしておく必要があるので、1 に対して、1.2となっています)。

ちなみに実際の箱
こんな感じで出来上がっています。接続部分は、鉄のアングルで、内側から止めています。

DIY素材の購入
大体のサイトで、cm単位で木を切った状態で送ってくれるので、今回の箱とかでは、鋸刃一切使っていません。ので、滅茶簡単です。
箱の素材は、下記で購入しました。
ここの素材は、サイズに割と制限があって、設計してると、パズル作ってるみたいになってしまって微妙なときがあるんですが、よく使っています。
自由なサイズで注文するなら、下記のサイトとかが良いと思います。簡単な加工も依頼できますし、希望すれば端材をもらえます。
終わり
DIYするときは、割と簡単なものでも、OpenSCADで設計するようにしています。紙に書くより正確だし変更が容易。moduleを作っておけば、注文するものがわかりやすい。3Dの図としてできあがると完成イメージが湧くので良いです。
また、大きなものだと、作成する以外の物(冷蔵庫とか、既存の棚、天井とか)とかもOpenSCADで表現してやると良いと思います。
例として、以下は、うちのキッチンに棚を作るときに用意したものです。

天井の段差、冷蔵庫、電子レンジ、食器棚、蓋をあけた炊飯器とかを雑に表現していますが、これくらいでも作っておけば、随分イメージがわきます。思ったよりものが入りそうにないなーとか...。
というわけで、OpenSCAD非常におすすめですよ。
参照
OpenSCADのマニュアルは下記にあります。
Nanocで全文検索を実装する
いくつかNanocの記事を書きましたが、検索がないと、実際問題使えないですよね。
というわけで、Googleで検索してみましたが、下記が見つかるくらいでした。
上記からたどったところ、下記のようなものがあれば、なんとかなりそうというところですが...... 元にしているNanocのバージョンが古いのと、英語のみを対象としているようなので、これを元に自作してみました。検索の実装自体はあまり変えていません。
lib/search.rb
# coding: utf-8 require 'json' require 'nokogiri' # 下記は適当に変えてください $ROOT_PATH = ENV.fetch("SITE_ROOT"){Dir.getwd + '/output'} # search-data.js.erbのMAX_WORD_LENと合わせる $MAX_WORD_LEN = 3; # item が一つのドキュメント def search_terms_for(item) # md 以外は除外 if item.identifier != nil && item.identifier.ext != nil && item.identifier.ext == 'md' # HTMLになった内容を取得 content = item.reps.fetch(:default).compiled_content doc = Nokogiri::HTML(content) # 対象とするタグが足りなければ増やしてください full_text = doc.css("td, pre, div, p, h1, h2, h3, h4, h5, h6").map{|el| el.inner_text}.join("").gsub(/ /, '') # $MAX_WORD_LEN文字ずつに区切った組み合わせの文字をindexとしています "#{item.identifier.without_ext}#{item[:title]}#{item[:meta_description]}#{full_text}".each_char.each_cons($MAX_WORD_LEN).map{|chars| chars.join } end end def search_index # 後で、idとページ情報を紐付けるのに使います id = 0; idx = { "approximate" => {}, "terms" => {}, "items" => {} } if @items == nil return idx end @items.each do |item| # 上で定義した、search_terms_forを使って、$MAX_WORD_LEN ごとに区切られた単語の配列を取得 result = search_terms_for(item) if result == nil next end result.each do |term| # termにマッチする id を入れておく入れ物 idx["terms"][term] ||= [] idx["terms"][term] << id # wor がtermの場合、 w, wo も検索対象とするための処理 (0...term.length - 1).each do |c| # term の 0番目からc番目までを、subtermとします subterm = term[0...c] idx["approximate"][subterm] ||= [] unless idx["approximate"][subterm].include?(id) idx["approximate"][subterm] << id end end end url = $ROOT_PATH + "#{item.identifier.without_ext}"+".html" # items に id と title, url等の情報を紐付けて持っておきます idx["items"][id] = { "url" => url, "title" => item[:title] || item.identifier.without_ext, "crumb" => item[:crumb] } id += 1 end idx end
content/search-data.js.erb
このJavaScriptの一番最後にある、<%= search_index.to_json %>; で、lib/search.rbの search_index から返されたものをJSONに変えて、埋め込んでいます。
埋め込まれるのは、具体的には、下記のようなJSONですね。
{ "approximate": {"w": [0,1,2], "wo": [0,1,2]}, "terms":{"wor": [0,1,2]}, "items": { "0": {"url":"/path/to/page1", "title1": "title1", "1": {"url":"/path/to/page2", "title2": "title2", "2": {"url":"/path/to/page3", "title3": "title3" } }
実際に検索を行うJavaScriptの実装です。
// lib/search.rb の $MAX_WORD_LEN と合わせる const MAX_WORD_LEN = 3 function unique(arrayName) { let newArray = new Array(); label: for (let i = 0; i < arrayName.length; i++) { for (let j = 0; j < newArray.length; j++) { if (newArray[j] == arrayName[i]) continue label; } newArray[newArray.length] = arrayName[i]; } return newArray; } function search(query, callback) { let terms = $.trim(query).split(/\s+/); let matching_ids = null; let l = terms.length; for (let i = 0; i < l; i++) { let j = i for (;terms[j].length > MAX_WORD_LEN;) { // MAX_WORD_LEN文字までのindexなので、その文字数を超えた場合は、雑に別にする let s = terms[j] terms[j] = s.slice(0, MAX_WORD_LEN); terms.push(s.slice(MAX_WORD_LEN)); j = terms.length - 1; } } for (let i = 0; i < terms.length; i++) { let term = terms[i]; let exactmatch = index.terms[term] || []; let approxmatch = index.approximate[term] || []; let ids = unique(exactmatch.concat(approxmatch)); if (matching_ids) { matching_ids = $.grep(matching_ids, function(id) { return ids.indexOf(id) != -1; }); } else { matching_ids = ids; } } callback($.map(matching_ids, function(id){ return index.items[id]; })) } let index = <%= search_index.to_json %>;
content/search.haml
下記が、検索ページになります。
- content_for(:javascripts) do %script(type="text/javascript" src="/javascripts/search-data.js") %script(type="text/javascript" src="/javascripts/jquery.url.packed.js") :javascript $(function(){ let getQuery = decodeURIComponent($.url.param("query")); let q = $.url.param("q") || getQuery; if ( q != '' ) { let query = q.replace("+"," "); $('input#q').attr('value', query); search(query, displayResults); } $('input#q').keyup(function(){ search(this.value, displayResults); }); }) function displayResults(items) { if (items.length > 0) { let html = "" for (let i = 0; i < items.length; i++) { html += '<li><a href="'+items[i].url+'?h=' + $("#q").val().replace(' ', '%20') + '">'+items[i].title+'</a></li>'; } $('ol#results').html(html) } else { $('ol#results').html("<li class='none'>Nothing found.</li>"); } } %input#q{:type => "text", :placeholder=>"Search"} %h2 Results %ol#results %li.none Please enter a search term.
実際の検索
自前のものが用意できれば良かったのですが、最初に貼っていたコードのサイトを貼っておきます。ほぼほぼ似たような感じで動きます。
欠点
やむなしですが、search-data.js.erb からできあがる search-data.js は、ページ数が多いとサイズが大きくなってしまいます。 553ページほどあるところで試しましたが、18MBくらいにはなりました。
ですが、読み込んでしまえば、速いので、そこはやむなしとします。
ページが少なければ、そこまで大きくもなりませんし、問題にはならないかと思います。